










 AI智能应用开发
AI智能应用开发 AI大模型开发(Python)
AI大模型开发(Python) AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+机器人开发
AI嵌入式+机器人开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作与直播运营
AI视频创作与直播运营 微短剧拍摄剪辑
微短剧拍摄剪辑 C/C++
C/C++ 狂野架构师
狂野架构师


全部 大数据新闻动态 大数据技术文章 大数据常见问题 技术问答
-
-
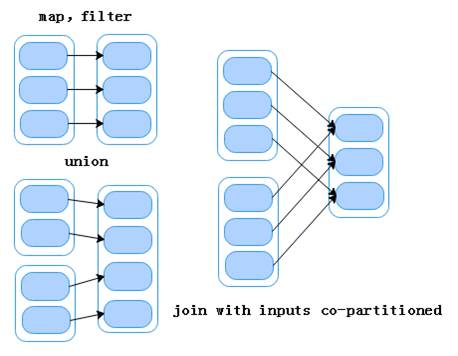
两种RDD的依赖关系介绍
在Spark中,不同的RDD之间具有依赖的关系。RDD与它所依赖的RDD的依赖关系有两种类型,分别是窄依赖(narrow dependency)和宽依赖(wide dependency)。 查看全文>>
大数据技术文章2021-01-05 |传智教育 |spark RDD,RDD的两种依赖关系
-

大数据离散流是什么?
Spark Streaming提供了一个高级抽象的流,即DStream(离散流)。DStream表示连续的数据流,可以通过Kafka、Flume和Kinesis等数据源创建,也可以通过现有DStream的高级操作来创建。 查看全文>>
大数据技术文章2021-01-05 |传智教育 |DStream,离散流,DStream是什么
-

Scala重写父类有哪些注意事项?重写代码演示
Scala和Java类似,只允许继承一个父类。不同的是,Java只能继承父类中非私有的属性和方法。而Scala可以继承父类中的所有属性和方法,子类拥有父类的所有特征。但是Scala在子类继承父类的时候,有以下几点需要注意: 查看全文>>
大数据技术文章2020-12-30 |传智教育 |scala子类继承父类,scala继承
-
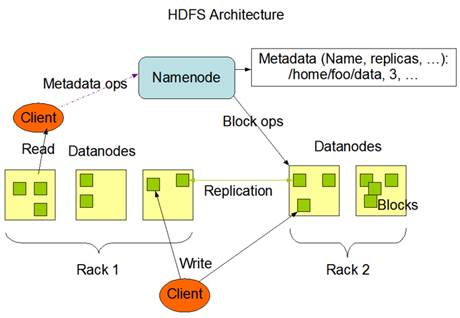
HDFS存储架构中主从节点关系?工作原理是什么?
HDFS采用主从架构(Master/Slave架构)。HDFS集群分别是由一个NameNode和多个的 DataNode组成。其中,NameNode是HDFS集群的主节点,负责管理文件系统的命名空间以及客户端对文件的访问;DataNode是集群的从节点,负责管理它所在节点上的数据存储。HDFS分布式文件系统中的NameNode和DataNode两种角色各司其职,共同协调完成分布式的文件存储服务。 查看全文>>
大数据技术文章2020-12-30 |传智教育 |HDFS,NameNode分布式文件系统,储存架构
-

Hadoop安装教程,8大安装目录的内容和作用分别是什么?
Hadoop是Apache基金会面向全球开源的产品之一,任何用户都可以从Apache Hadoop 官网下载使用该产品。本书将以编写时较为稳定的Hadoop2.7.4版本为例,详细讲解Hadoop的安装步骤。 查看全文>>
大数据技术文章2020-12-29 |传智教育 |Hadoop安装步骤,Hadoop安装目录的作用是什么
-
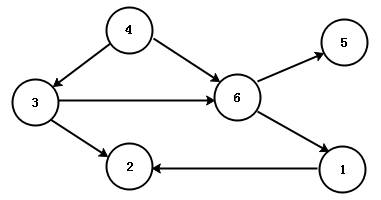
DAG是什么?DAG有向无环图实例讲解
DAG(Directed Acyclic Graph)叫做有向无环图,DAG是一种非常重要的图论数据结构。如果一个有向图无法从任意顶点出发经过若干条边回到该点,则这个图就是有向无环图,接下来通过几个例子,我们来详细了解下DAG有无环向图。 查看全文>>
大数据技术文章2020-12-29 |传智教育 |DAG,有无环向图,什么是DAG
-

Spark Streaming工作原理是什么?
Spark Streaming支持从多种数据源获取数据,包括Kafka、Flume、Twitter、ZeroMQ、Kinesis 以及TCP Sockets数据源。当Spark Streaming从数据源获取数据之后,则可以使用诸如map、reduce、join和window等高级函数进行复杂的计算处理,最后将处理的结果存储到分布式文件系统、数据库中为了可以深入的理解Spark Streaming,接下来,我们对对Spark Streaming的内部工作原理进行详细讲解。 查看全文>>
大数据技术文章2020-12-28 |传智教育 |Spark Streaming,Spark Streaming工作原理
-

传智教育零基础大数据入门视频教程
从0开始学习大数据课程,想了解linux、kettle、BI、mysql、从基础到实践,通过知识点 + 案例教学法帮助你想你想迅速掌握大数据。提取码:ir0t 查看全文>>
大数据技术文章2020-12-23 |传智教育 |大数据入门视频教程
-

















江苏传智播客教育科技股份有限公司 版权所有Copyright 2006-2024 All
Rights Reserved
苏ICP备16007882号营业执照增值电信业务经营许可证出版物经营许可证 苏公网安备 32132202001156号
苏公网安备 32132202001156号
免费领取黑马程序员AI通道专属星级课程资料
